2020年8月現在のWEB情報収集に関する雑感
日々進化するサーバーの仕様と
そのサーバーからデータを効率よく収集しようとする側の戦いは
ときにドラマチックなこともあり感慨深いものがあります(大げさ)。
今記事ではそのような収集行為(スクレイピング行為)に関する方法と対策の変遷と
筆者の知る限りの最近(2020年8月)の動向をご紹介させていただきます。
尚、この記事は「スクレイピング行為」を助長させることを目的としているわけではなく
健全(迷惑を掛けず)に業務を遂行するためのまとめだと理解ください。
併せて、雑感の範囲(無責任)でまとめておりますので詳細の理解はググっていただき正しい理解、判断をいただければと思います。
WEBサイトからの収集行為(スクレイピング行為 以下略)とは何か
例えば旅行で行く先の美味しいご飯屋さんを紹介する個人ブログサイトがあったとします。
しかしながら1店舗1記事になっており、情報を参考とするために旅行先の10店舗ほどをワードへ貼り付けドキュメント化し、印刷したことなど経験があるかと思います。
一般的にはこのような行為もWEBサイトからの収集行為に該当します(人力によるコピペ)。
もちろんこのような行為は健全な行為で、むしろ提供元も使っていただけてよろこんでいるではず(?)です。
でも、この公開ブログには全国の津々浦々が網羅されており
全記事数が10,000余軒あったとします。旅行先ならず今後の参考に、あるいはそれを再編集して必要な人へ転売を考え総当たりで収集、更に効率を追求しプログラムを作成し実行をすると、場合によっては不正行為に該当する場合があります。
※公開元利用規約や所有者からの訴えなどによる。詳しいことは詳しい方に聞いてください。
そもそも対策を取るサーバーの意向とは
対策を取る理由は簡単で「迷惑だから」が挙げられます。
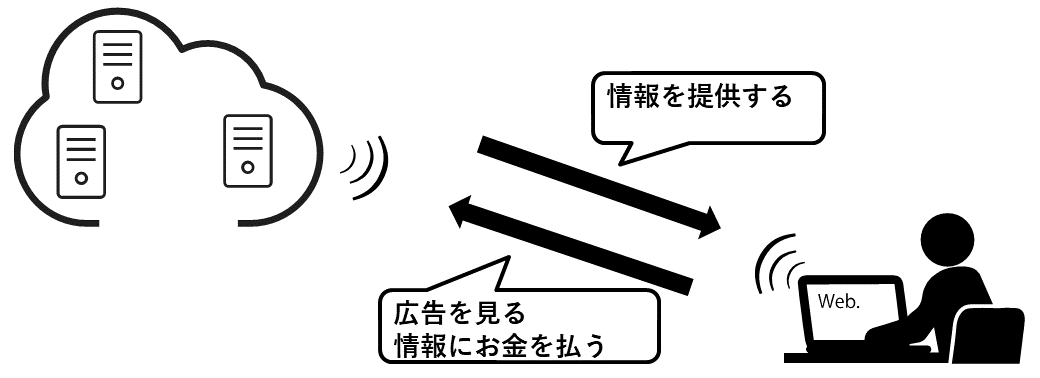
例えばサイトへアクセスする度に広告が表示され広告を見てもらえると運営側に利があります。
しかしながら、機械的な収集はそういった「見せる側」と「見る側」の暗黙の了解を無視することになり「迷惑行為」と受け取られます。
同様に情報そのものに「価値」があるサイトもお金を払わずに収集されることを良しとしませんので積極的な対策をしています。
例:お金を払った会員のみが閲覧できるサイトをURLで直接アクセスし無償で閲覧する、など
具体的な収集方法
法的な話は専門外のため、本旨に沿って次に進めます。
以下具体的な収集方法とその対策の変遷を個人的にまとめてまいります。
人によるコピペとその対策
【取る側】
もっとも簡単な方法です。テキストを選択して右クリックからのコピー
ワードやエクセルを選択して右クリックからの貼り付け
(またはCtrl+C→Ctrl+P)
【サーバー側】
これらに対する対策は「右クリック禁止」などのjavascriptプログラムなどが一般的です。
同様に「PDF化」や「名前をつけて保存」などもありますが、似たような対策で防ぐことが可能です。
但しやり過ぎると「不便さ」が増加するため、サイト来訪者が減少するというデメリットも。
個人的にはこのほうが強いと感じております。

Wgetやcurlによる機械的取得とその対策
【取る側】
詳細はWikipediaにおまかせします。
30年ほど前に開発された鉄板の収集方法で普遍的とも言えます。
習得にはプログラミングスキルを要しますが、できるようになって損のない技術なので興味のある方は是非習得を。
ざっくり言えばこのプログラミングを活用すると10,000軒のページ収集など、数時間でエクセルなどにダウンロードが可能です(法的、またサーバー事情を度外視の場合)。
少し掘り下げて説明をすると、サーバーにアクセスした際のHTML情報をすべて収集できるため、そのソースコードを構造解析すれば目的の情報が得られます。
【サーバー側】
一つはWgetやcurlによるアクセスを禁止する設定です。ある意味これがサーバー側の初歩的な対策と言えます。
また、もう1つが「見える環境をjavascriptで作成する」方法です。
これは強力な対策でサーバーにソースを書き出さず「ブラウザにのみ結果を表示する」という方法で、従来のサーバーへ機械的にアクセスする方法をことごとく対策しました。
しかしながら副作用もあり現状がどうかは把握しておりませんがgoogleなどの検索に記事がヒットしない、などのアクセス低下を招く場合もあります。

ブラウザを経由した機械的取得とその対策
【取る側】
これが最近の、ちょっと前のトレンドです。
python × Selenium × WebDriverなどは少し調べると様々な方法が紹介されています(例によって詳細はWikipedia)。
先に記載した「ブラウザにのみ結果を表示する」ことを踏まえ収集方法に「ブラウザ」を経由させました。
本来はサイト開発のためのテスト用ソフトウェアという位置づけだったみたいですが、昨今のスクレイピングといえばこの方法が一般的になりつつあります。
【サーバー側】
恐ろしいことに、この対策は比較的簡単で「Selenium」からのアクセスを禁止するという設定で解決します。
ここまで説明しておいて「これだけ?」という感じですが、Selenium関連は人気になり過ぎてしまい「明らかなロボットですよね」と判断されるようになったみたいです。

余談 reCAPTCHAについて

このようなページを見たことがある方は昨今多いのではないでしょうか。
これらは一連の「ロボット対策」と言われるもので
機械的な収集を目的としたアクセスに対抗するために開発された方法です。
つまりアクセスの仕方が「ロボットっぽい」場合に発動し認証が求められるので
今後はいかに「人間っぽい」収集の仕方が求められるか、の良い例かと思います。
余談の余談ですが、これを突破する方法(サービス)も存在していて
カラクリは「全国の有志が変わりにreCAPTCHAを手作業で突破する」という方法です。
暇つぶしに有志側に立ってお小遣いを稼ぎたい方は是非調べてみてください。
RPAを用いた機械的取得とその対策
【取る側】
コピペもダメ、サーバーへの直接アクセスもダメ、ブラウザを介してもダメ、となった場合
現状はどういった方法で解決すればいいでしょうか。
公開側が禁止しているのは「機械的な収集」であり「人間がやったような機械の収集」は検知できません。
ここで登場するのがRPAによる収集方法です。
例によってRPAの説明は詳しい方へ一任します。
RPAを活用することでざっくり言えば「手作業の早い人間が収集している」ように見せるわけです。
これが2020年8月現在の最適解なのではないかと筆者の狭い世界観では考えます。
【サーバー側】
これを禁止させようとするならば「閲覧する人は禁止!」という本末転倒な設定になります。
これではWEBサイトを運営する意味がありません。
現状講じられている対策としては「時間あたりのアクセス数が著しく多い場合」や
「ページ繊維の行為に規則性がある」方に対して「ロボットですか?」と定期的にreCAPTCHAを送るなどが挙げられます。
筆者はこの巡り巡って人間的な行為に戻ったあたりが感慨深く、今記事を書く動機になったと申し添えます。

結論 情報は買いましょう
ここまでの説明でサーバー運営者とスクレイパーによる飽くなき戦いの一端を感じていただけましたでしょうか。
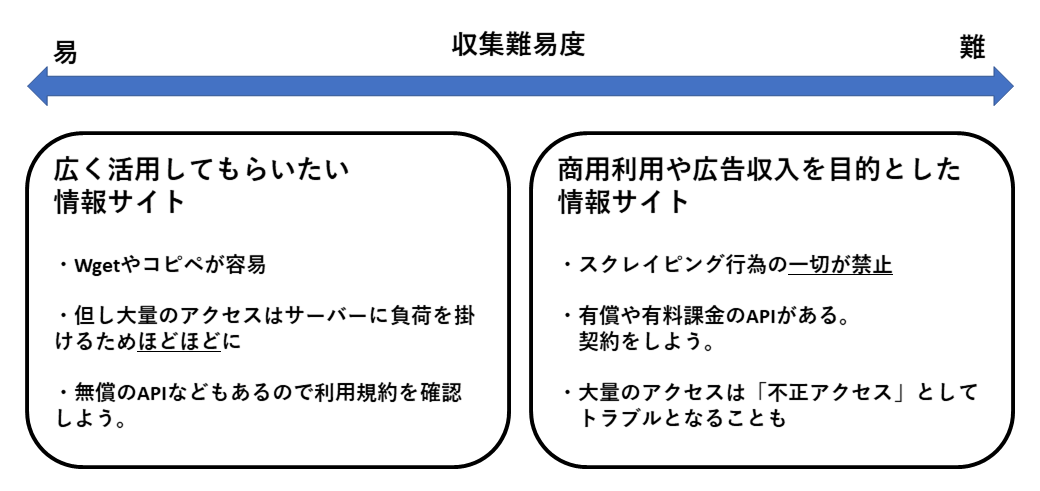
正直現状でも大半のWEBサイトは上記対策の1つも講じておりませんので普通にコピペ、wgetなど可能です。
しかしながら「有償に類する情報資源」に関しては上記以外にも様々な方法で講じられており、まさにイタチごっこと言えます。
筆者の見解としては「有償に類する情報資源」に関しては敬意を払い適切な方法を取り、APIによるアクセスや有償による購入を推奨しております(これが言いたかった)。
APIの契約などであれば上記のような小手先を弄さずともマニュアル通りに収集・運用ができますし、有償であれば公開側も「取りやすい」よう配慮をしていただけますので
双方が笑顔で情報の取り引きができます。
したがって、この長文をここまで読んでいただくと
弊社のスタンスが「勝手に取るよりは買いましょう」というスタンスであることがおわかりいただけたかと思います。
研究機関の業務が多い関係で不正な情報収集が倫理上認められない場合もあり
また依頼主がそのような背景を把握していない場合などもあるため、こういった記事が健全な収集作業の参考になれば幸いです。
筆者としてはまた一年後にこの記事を読み返したとき、時代がどのように変わっているのか個人的に楽しみにしております。
最後の最後に、RPAはけっこうすごい
情報収集に関しては倫理上の観点から「買いましょう」というスタンスを取らざるを得ませんが
昨今増えている相談で
「データベースの入れ替えがあるが直接転送できないので
Aのサイトにログインして情報を表示して
BのサイトにログインしてAの情報を入力してほしい」
というケースも時々いただきます。
こういう処理はRPAやブラウザを介したプログラムが大得意なところですのでまだまだ需要があると思っています。
サイトから情報収集をする際にはどのような方法が「運営側に迷惑を掛けないか」などに関しても提案しておりますので、気になる方はお問い合わせください。