F分布について|Excel(エクセル)で学ぶデータ分析ブログ
■F分布とは?
Wikipedia より(一部編集)
“F分布(F-distribution)とは、統計学および確率論で用いられる連続確率分布。スネデカーのF分布(Snedecor’s F distribution)、又はフィッシャー-スネデカー分布(Fisher-Snedecor distribution)とも。”
F分布のFは統計学を学ぶ上でよく登場するロナルド・フィッシャーさんのFです。数学の世界では発明者の名前をつけた定理や公式が多くありますが、筆者は正直覚えづらいのでなんとかならないか、と常々思っています。
F分布も個人的には「比率の分布」とかにしてもらうと覚えやすいかなぁと思いますが、まぁ改称は無理でしょう。
カイ二乗分布を理解すると、F分布の理解も早いと思い ますので、参考にして下さい。
今回は公式から説明します。
自由度d1のカイ二乗分布U1と自由度d2のカイ二乗分布U2の2つの変数の比
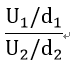
は自由度(d1、d2)のF分布に従います。
試しに乱数を使ってシミュレーションしてみましょう。
■F分布の概要(正規分布、カイ二乗分布からの導出)
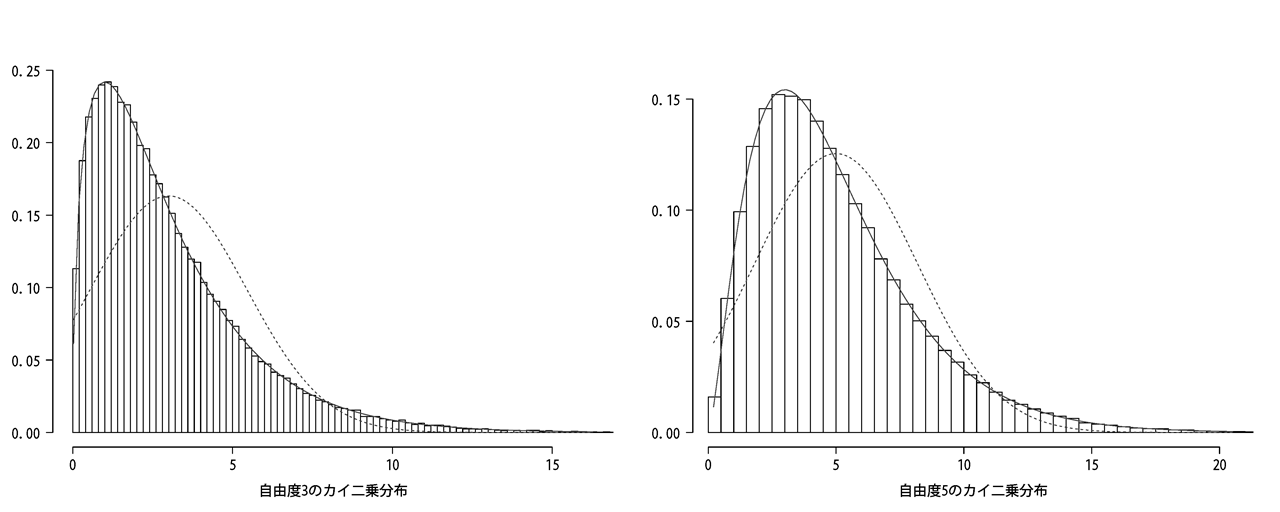
標準正規分布(左側)の分布から、ランダムに3個値を抽出したとします。
その値を二乗して3個すべてを合計する、という処理を50,000回ほど繰り返すと
自由度3のカイ二乗分布に従う分布図を得ることができました(右側)。
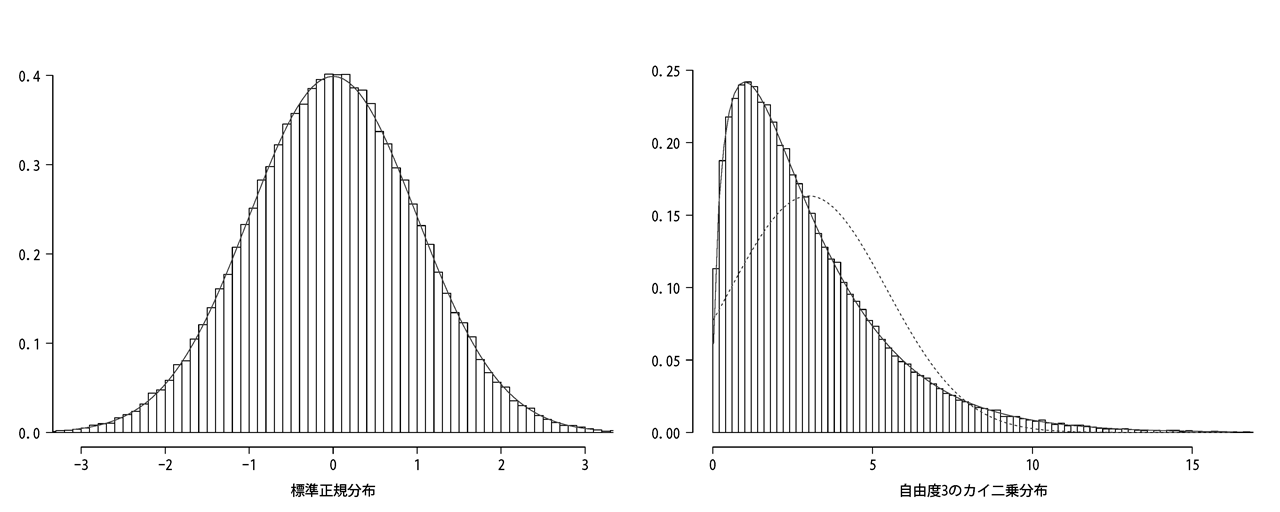
こんどは同じような処理を自由度5にして作成しました(右側)。
ここで、F分布の定義を再確認します。
自由度d1のカイ二乗分布U1と自由度d2のカイ二乗分布U2の2つの変数の比
は自由度(d1、d2)のF分布に従います。
つまり、このカイ二乗分布を導出する過程で計算された統計量に対して「自由度で割る」という処理をそれぞれで行えばいいということになります。
それを更にそれぞれで割る・・・書いていてよくわからなくなりました。

つまりこんな処理をすればいいということで、早速やってみましょう。
左が正規分布からの導出で、右は計算の過程がややこしいのでカイ二乗分布の乱数を用いて計算した分布図です。
どちらも同じ結果となるため、これだけ見ると信憑性がありませんが、そこはご愛嬌ということで。
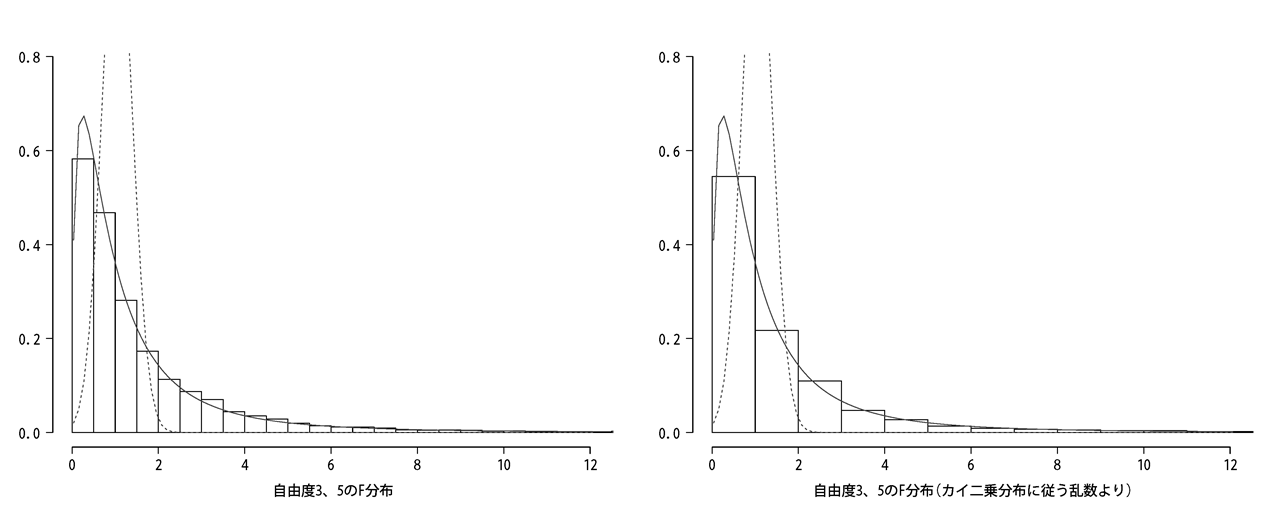
とにもかくにも、目的としていたF分布に従う結果を得ることができました。めでたし×2。
■エクセルで計算した場合
エクセルの場合は、かなり骨太な関数を書きます。
【((B$1/B$2)^(B$1/2))*(GAMMA((B$1+B$2)/2)/(GAMMA(B$1/2)*GAMMA(B$2/2)))*(($A3^((B$1-2)/2))/((1+(B$1/B$2)*$A3)^((B$1+B$2)/2)))】
カイ二乗分布と同様にガンマ関数を使っています。これをベータ関数というもので作成することもできるのですが、当ブログでは未だ紹介しておりませんのでベータ関数の計算は割愛させていただきます。
べつにこんな強烈な関数を書かずとも、
【F.DIST($A3,H$1,H$2,0)】と書くだけで同じ結果は得られるのでご安心下さい。
■F分布の使いみち
だけを見たときに「だからなんだよ」と思ったあなたは、きっと筆者とおいしいお酒が飲めると思います。
でも、下記のように変換をすると、案外「スゲェ分布じゃねぇか!」と驚くかもしれません。
2つの正規母集団の母分散が等しい(σ1^2=σ2^2=σ)ならば、上式は2つの標本の不偏分散(V)の比のみの関係式となり、
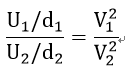
が成り立ちます(証明は省略)。
つまり、同じ不偏分散の値からランダムに抽出した変数の標本分散の比率は平均値などに関係なくF分布に従うということです。
この関係式は、裏を返すと「F分布に従わない場合は違う不偏分散の分布どうしから得た変数じゃないですかね??」という意味を含んでいるわけですから、
その性質を利用してF検定(や分散分析)は説明力を保持していると考えられます。
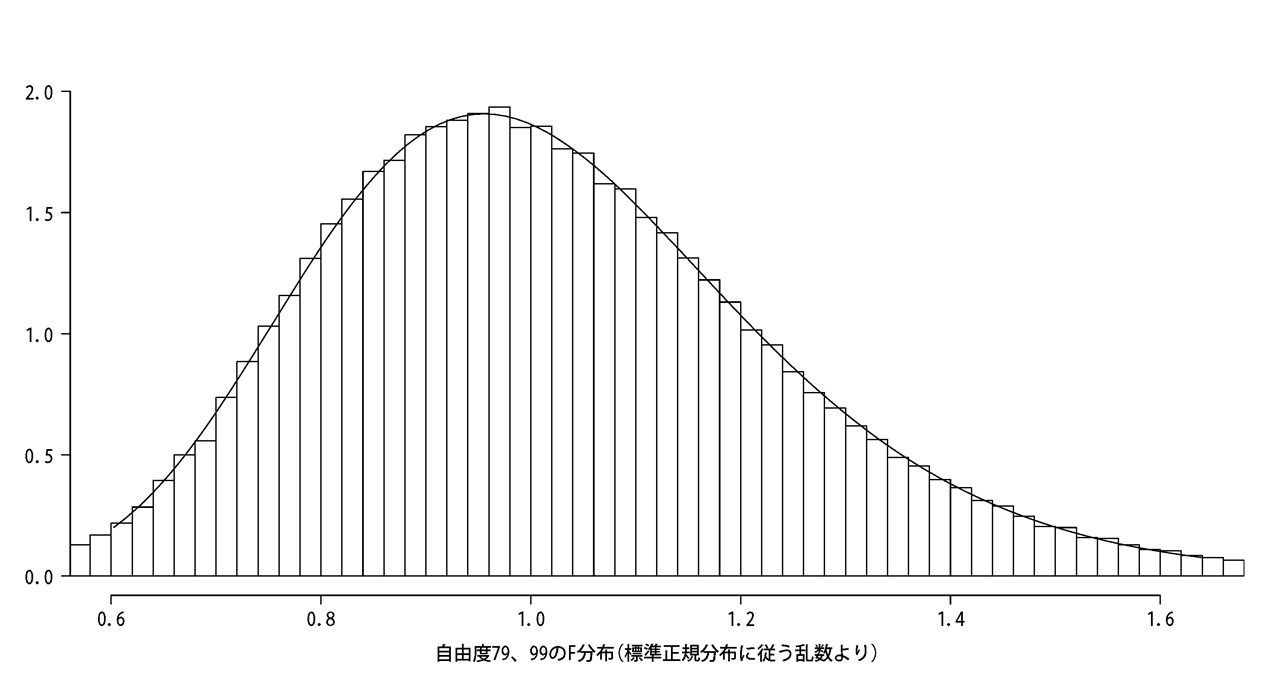
下記は標準正規分布の乱数をそれぞれ80個、100個出力し、標本分散で割った値を分布しています。
標本分散でF分布を計算するときには出力した個数をn-1するのがお約束なので、自由度は79,99となりました。
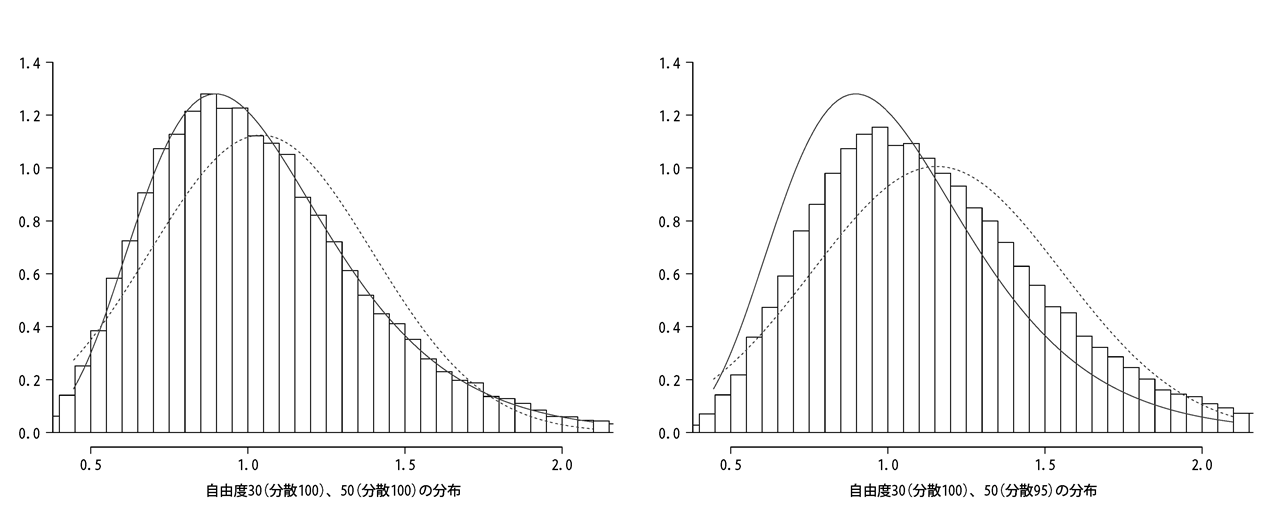
同じ条件で、標本分散の値だけ変えて出力した結果が下記です。
左は等分散、右は5だけ異なる標本分散の乱数で割ったものです。
結果はF分布とは異なる分布となりました。
この等分散性を確認するためにF分布は利用されます。
例えば回帰分析など。回帰分析で得た直線が実値とどれだけずれている(誤差がある)かを計算し
その値の等分散性を検定し、異なるようであればその直線は別の因子の影響を受けているだろう、と判断することになります。
分散分析であれば、多群比較の際に平均値がどれだけ中心の平均値から離れている距離(誤差)かを計算し、
その値の等分散性を検定し、異なるようであればその多群は別の分布から得た値だろう、と判断することになります。
いかがでしょうか。F分布のすごさを感じていただけましたでしょうか。
■F分布の正規近似
はい。自由度が高くなるとF分布さんも近似します。
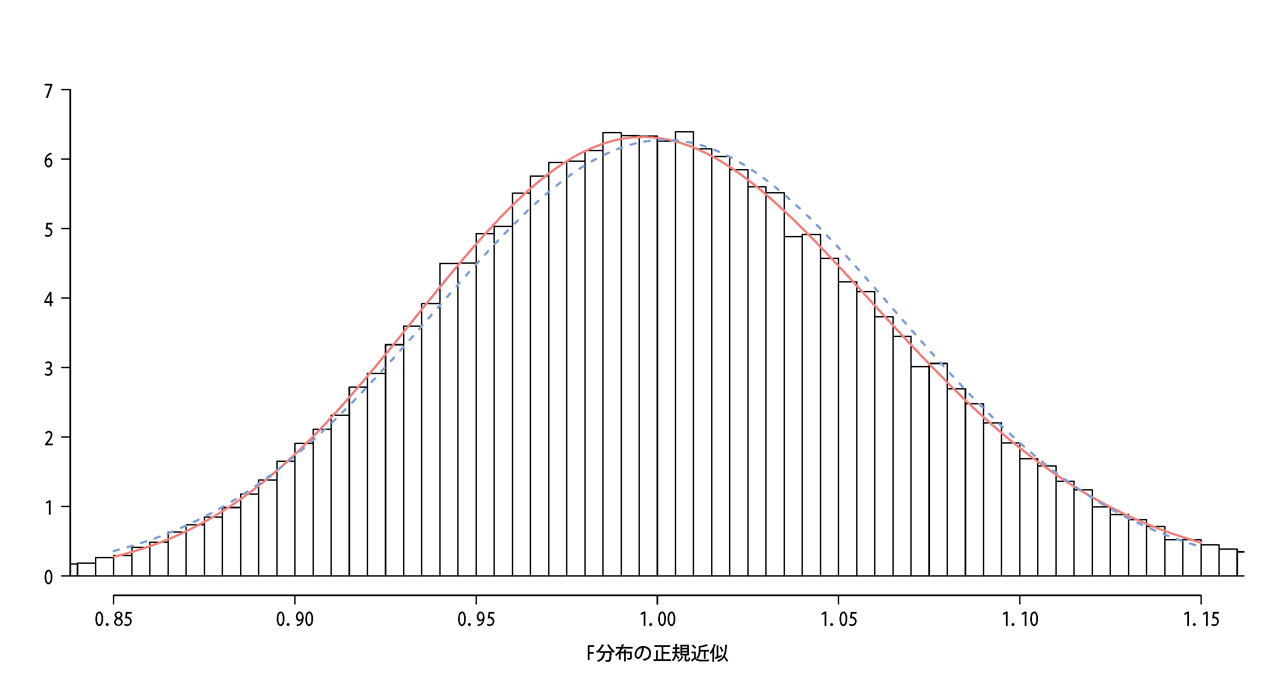
上図は自由度を1,000ずつにした分布です。ずっと破線を出し続けておりましたが、あとちょっとというところで一致しますね。
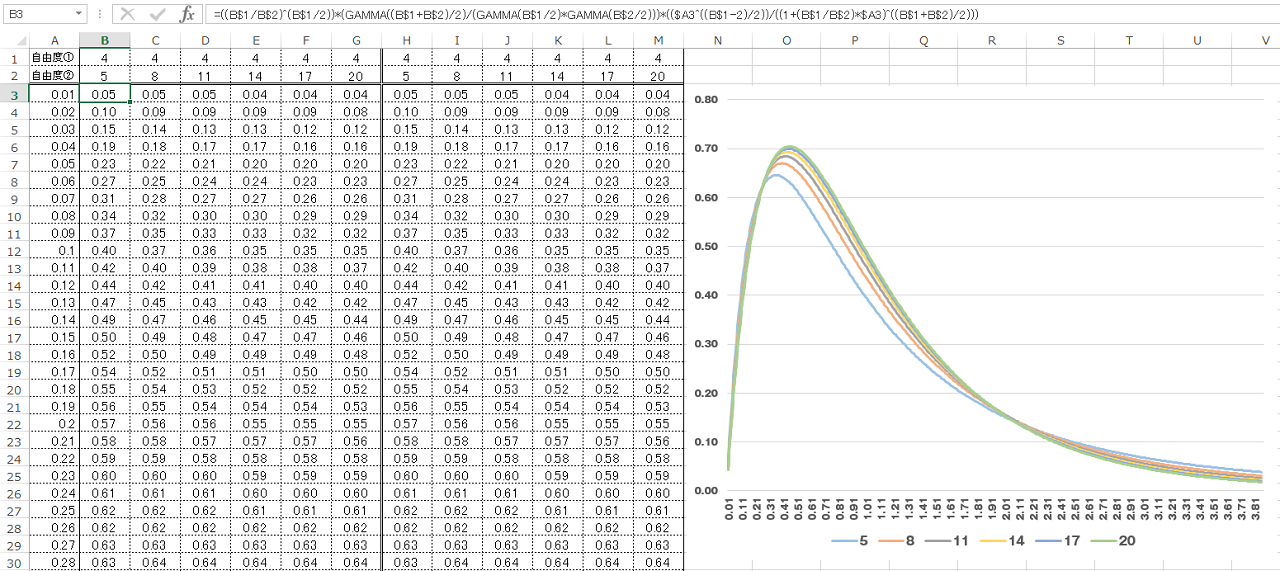
■感覚的にしっておくと便利な指標
計算してみた筆者がいうのもなんですが、下記はちょっと気持ち悪い図になりました。
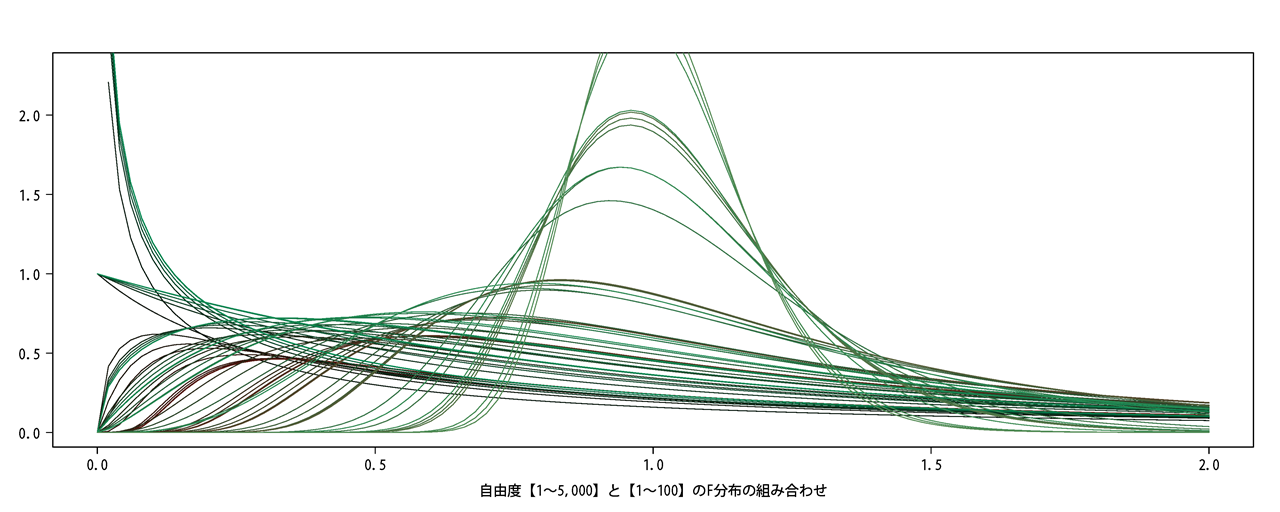
様々な自由度の掛け合わせでF分布がどのようになるかを色を変えてだしてみたんですが、
しつこいようですが気持ち悪いですね。
なにが言いたいかというと、自由度が高まると1を中心に正規分布に近似します。
また、統計量が2以上になるとほとんどの分布で0.05以下になるということです。
つまり、分散分析や回帰分析に掛けた際にP値計算をせずとも、統計量が2を越えていたら有意じゃね? と予想できるわけです。
(あくまで私見ですので、ご使用の際は用法用量を守って正しくご判断ください)